Series: Basic Intuitions of Machine Learning & Deep Learning for beginners
Chapter 7: Deep Learning’s Blind Spot Part 1 Underspecification
Originally published 16 February, 2021 By Michio Suginoo
Last Edited 21 February, 2021
Repeatedly, success stories of Deep Learning have been over-emphasized in the public domain in the past. Nevertheless, recently, blind spots of Deep Learning are gradually catching public attentions. I think that it is a healthy development for the responsible pursuit of Deep Learning. If we want to claim the ownership of its power, we need to shape a balanced understanding about Deep Learning: over its risks/shortcomings and its benefit.
In this short chapter, I would like to illustrate one of issues of Deep Learning: namely ‘Underspecification’. Although ‘Underspecification’ has been documented in the past, a recent paper published by a group of Google’s Data Scientists has drawn the public attention on this problem. Now, let’s start.
Recap: Gradient Descent
As a recap, hyperparamters play a significant role in storing and updating the learning properties of Deep Learning. In Chapter 4, we saw the learning mechanism of Deep Learning: how Deep Learning updates hyperparameters during the process of ‘Refine’ in the 3 step iteration cycle of ‘Try & Error & Refine’. This updating method was called Gradient Descent.
Click the video below to review the notion of Gradient Descent.
The method slides down the cost function’s landscape to reach the global minimum of the cost function. Yes, Gradient Descent is like a skiing along the downhill.
There are multiple difficulties in Gradient Descent: e. g.
getting trapped in a local minimum;
getting stack on a flat plane, called saddle.
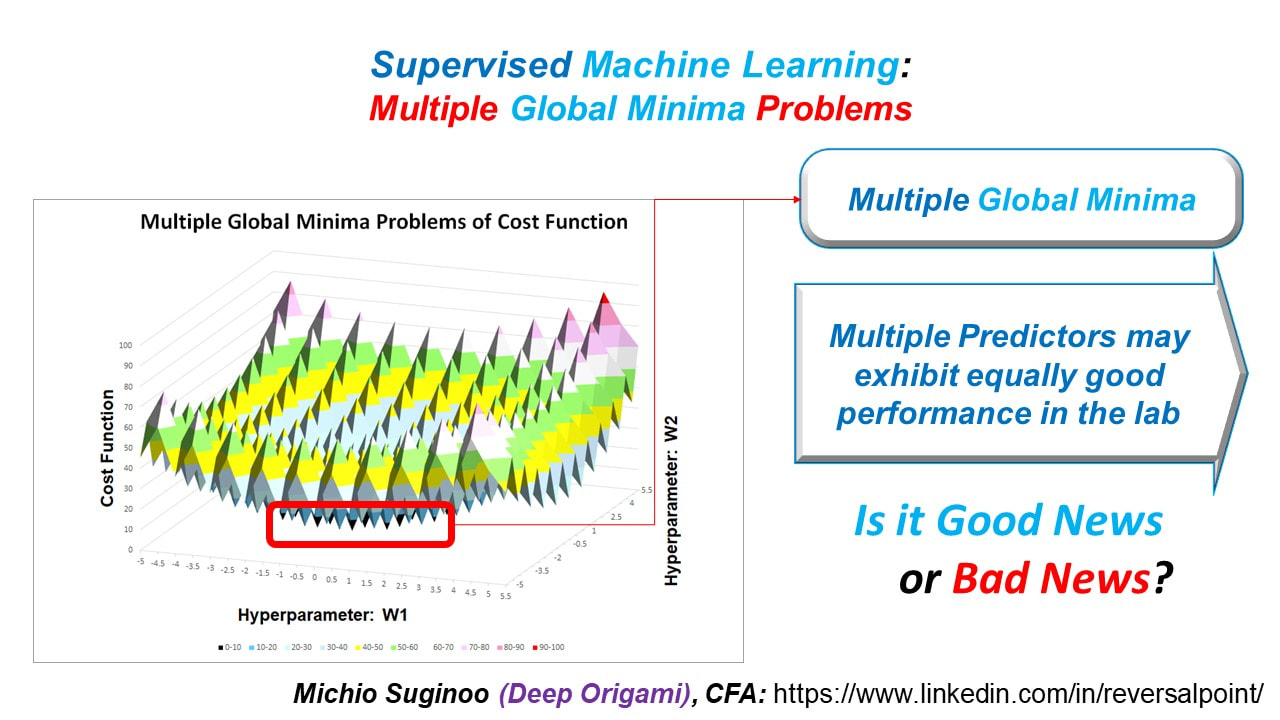
Now, I want to show you just one extreme example: the problem of multiple global minima.
Multiple Global Minima
When a cost function has multiple global minima, Deep Learning model generates multiple predictors that exhibit equally good performance in the lab.
Is it good news—is it that More is Better? Or is it bad News?
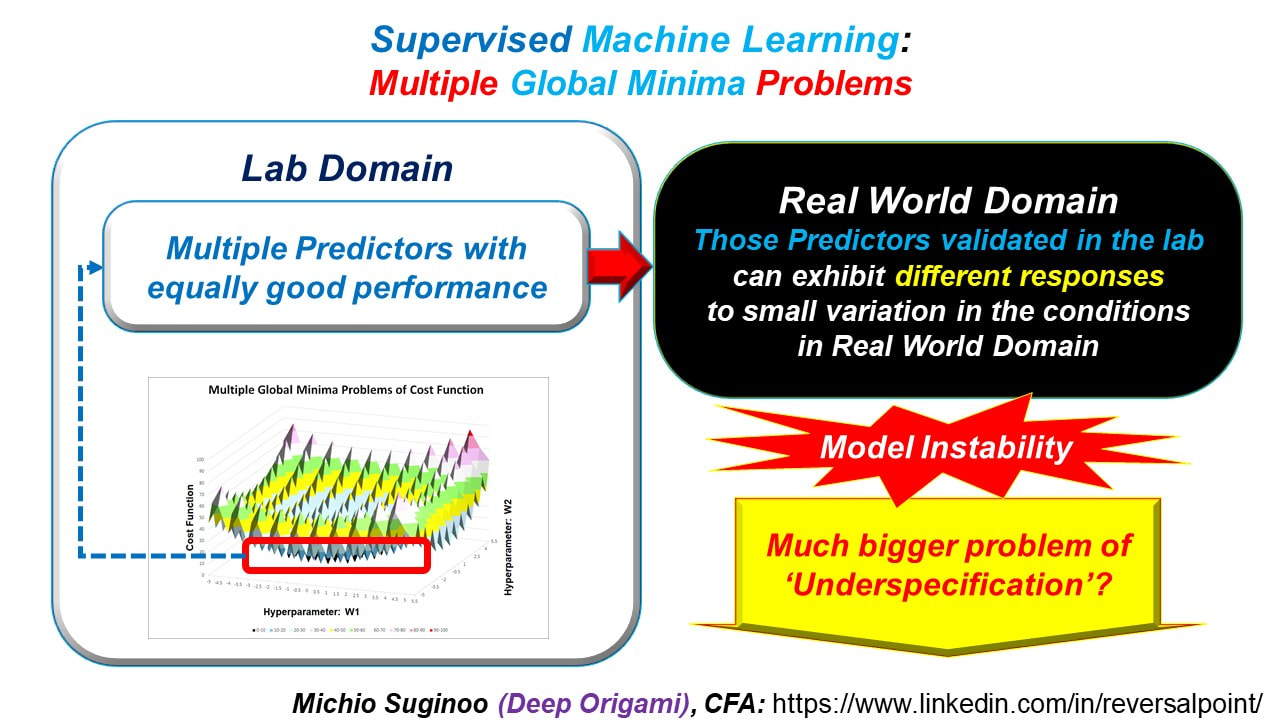
In the past, engineers have experienced difficulties with problems of multiple global minima.
They found out “those multiple predictors validated in the lab” can demonstrate very different responses to “small variations in the conditions in real world setting”. In other words, they demonstrate different sensitivities to a change in the given condition. This leads to Model Instability. The model instability in real world applications can be problematic.
Imagine, an application in Autonomous Navigation: since the environment keeps changing, it can result in accidental loss of life.
Some Scientists speculates that this problem is only a manifestation of a much bigger problem, called ‘underspecification’. Here, a precaution is that these two—"multiple global minima” and ‘underspecification’—are not identical: the former can be a manifestation of the latter, although it does not necessarily need to be always so: tricky.
Although the problem of ‘Underspecification’ has been documented for a long time, it is a recent Google paper, “Underspecification Presents Challenges for Credibility in Modern Machine Learning” (D’Amour, Heller, Moldovan, & et al, 2020), that widely drew the public attention to the issue.
In general, Standard ML Pipelines specifies only 3 factors:
a model specification, which is not the specification of rules that maps the features into the labels in a conventional algorithm sense.
a training dataset
and an independent and identically distributed (iid) evaluation procedure.
No more, No less. They stress the need for additional specification at least: “the evaluation process toady is agnostic and also needs to specify the particular inductive biases encoded by the trained model.”
In addition, they suggest that we would need to incorporate another layer of testing—such as perturbation and stress-testing to evaluate the sensitivities of the multiple validated predictors—into the model development process.
“Standard ML pipelines are built around a training task that is characterized by a model specification, a training dataset, and an independent and identically distributed (iid) evaluation procedure; that is, a procedure that validates a predictor’s expected predictive performance on data drawn from the training distribution. Importantly, the evaluations in this pipeline are agnostic to the particular inductive biases encoded by the trained model. While this paradigm has enabled transformational progress in a number of problem areas, its blind spots are now becoming more salient. In particular, concerns regarding “spurious correlations” and “shortcut learning” in trained models are now widespread …” Source: https://arxiv.org/pdf/2011.03395.pdf
I will leave you to explore the Google Paper for the details. The co-authors of the Google paper share their current findings of ‘Underspecification’ in their paper: https://arxiv.org/pdf/2011.03395.pdf.
After all, keep in your mind one popular definition of Machine Learning, an algorithm paradigm that learns without explicitly programmed. According to this popular view, ‘Underspecification’ appears deeply embedded in the very architecture of Machine Learning. The fundamental principle of Machine Learning might need to be revised in the future.
Raise awareness about the risk of using Deep Learning
Remember, in Chapter 1 we saw that, Machine Learning Paradigm emerged in the context of the limitation of the conventional algorithm paradigm, which requires programmers to set rules that maps features (independent variables) onto labels (dependent variables). Deep Learning can be very powerful especially when a given task is too complex for any conventional model to achieve.
On the other hand, it can be very deceptive: we are not sure if a generated model is robust or not. It can be also costly, incurring a massive carbon footprint. Overall, we need to subjective judgement regarding a balance between appreciating the benefit and alleviating the risk.
One obvious answer is to avoid Machine Learning as much as possible and try to find a solution within the conventional model domain, where models are built based on some kind of inductive and/or deductive formulations. If the complexity of a given task is manageable by some conventional models, choosing conventional models is definitely a reliable approach.
An enigma arises when the given task is too complex for us to find any solution within the conventional model domain. In such a case, Machine Learning might be the last resort, but would involve risks that we cannot imagine a priori. As of today, there is no guarantee about the robustness of a model generated by Machine Learning when it is deployed in real world domain. So, as of today, users need to make a subjective decision whether to take unknown risks to explore the power of Machine Learning: or whether they have deep enough cushion to absorb the worst negative consequence. There is no straightforward answer regarding how to strike a balance between the risk and the benefit of Machine Learning deployment.
Going forward, we need to establish a systematic ‘a priori’ method to evaluate the reliability and robustness of Machine Learning model.
Overall, Machine Learning, especially Deep Learning, is still in the process of evolution today.
The important thing for now is that we need to be fully aware that Machine Learning has some architectural issues. An astute user would be better off not blindly believing the output of Machine Learning. Blindly accepting its output would be like having a wild animal, like a lion, unleashed as a pet in your bedroom: in an unexpected moment, you can get hurt by your pet.
In order to claim the ownership of the power of Machine Learning, we need to understand its risks and domesticate it by restraining it. That is why human involvement is very essential in the assessment of Machine Learning Models. At least as of today, automation with Machine Learning is a scientific fiction: at least to me. In this context, we need to maintain a right mindset of critical and analytical thinking together with objective and independent conduct in the handling of Machine Learning.
My personal monologue on Specified Models in General
This last section is totally my subjective and open discourse. Please feel free to skip it and move on to the next chapter unless you are interested.
It is so true that the risk of ‘underspscification’ is deeply embedded in the architecture of Machine Learning and Deep Learning. Today, we still do not have come to a consensus regarding how to resolve it, although Google Data Scientists came up with their formulation as cited above.
Nevertheless, here is a fundamental question: are well-specified conventional models perfect?
This has been preoccupying me for a long time. I have two cases at least in mind to question this. Whether these cases serve as good examples or not, I would leave it to the readers’ judgement.
First, many conventional economic models, especially Neoclassical Economics, have excluded pollutions from the analysis in principle, treating them as externality. As a consequence, it encouraged short term gain at the expense of long term common goods: simply put “privatize the gain and socialize the cost” and created the world with massive environmental damages that we live in today. CO2 emission is just a tip of ice burg. Now, this is firing back to our economy. This raises a natural question if the past growth were ever possible if our system had imposed financial penalty on every environmental damage created.
As another case, monetary economics is predicated on the assumption of the neutrality of money. To me, every financial bubble, which we witnessed without any censorship, disproves this assumption. Money is not neutral: money causes long term consequences to real economy. I have been protesting on this in the public domain in the past without success: Despite numerous evidences, some economists still assume the neutrality of money today. It is becoming a sort of ‘Dogma’.
These two thoughts just make me wonder if there is such a thing, like a reliable “well specified model”. It seems to me analysts can embed some egregious assumptions in a model architecture to reduce reality to an expedient fabric: here, I am not generalizing that this is always the case.
While ‘underspecified’ models have problem, well-specified models are not free from issues: a wrong set of assumptions can take us to catastrophe as well. In addition, there are rampant cases of p-hacking in applications of established statistical models.
And a deeper question would be, can we set assumptions and/or specifications right anyway? Whatever models we have, they might only give us an illusion of knowledge and an illusion of control.
One thing for sure is: whatever models we have, regardless whether well-specified or underspecified, we are better off having deep understanding about the shortcomings of our tool to protect ourselves.
So far, we covered general topics of Deep Learning.
In the next chapter, I would like to give you some intuitions about two basic Deep Learning models: namely, Convolutional Neural Networks and Sequence Models.
Donation: Please feel free to click the bottom below to donate and support the activities of www.reversalpoint.com