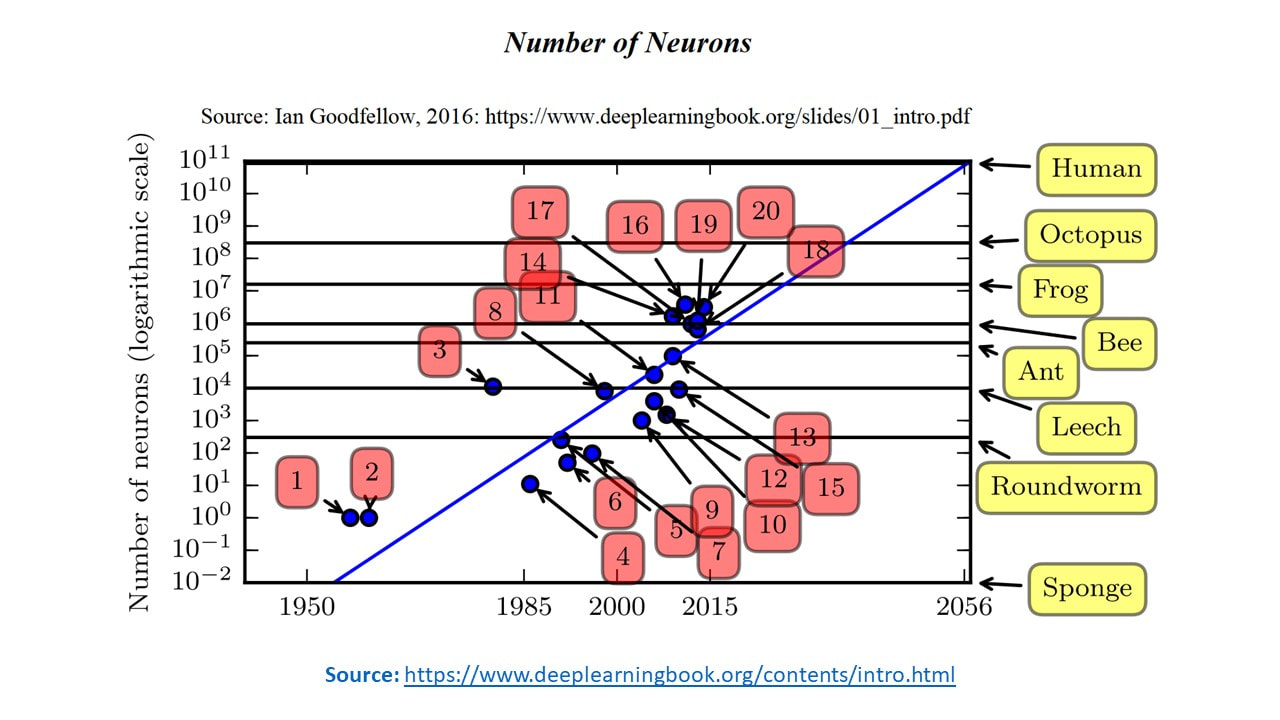
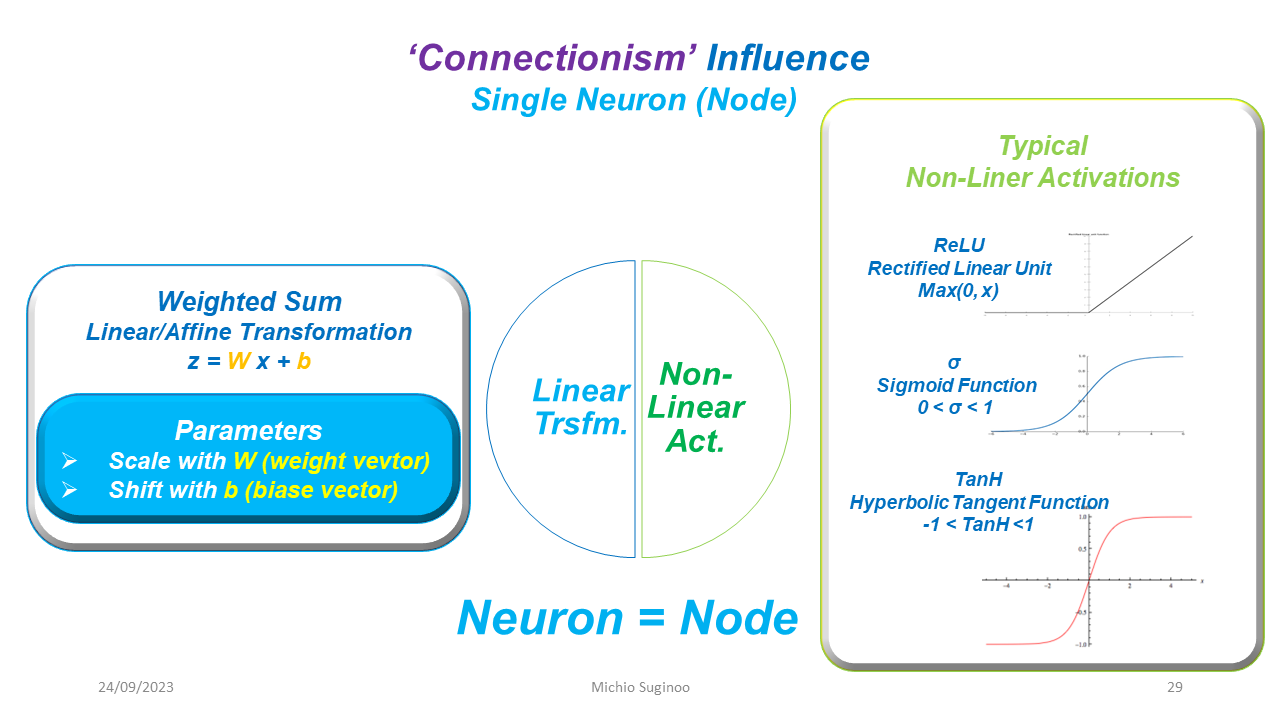
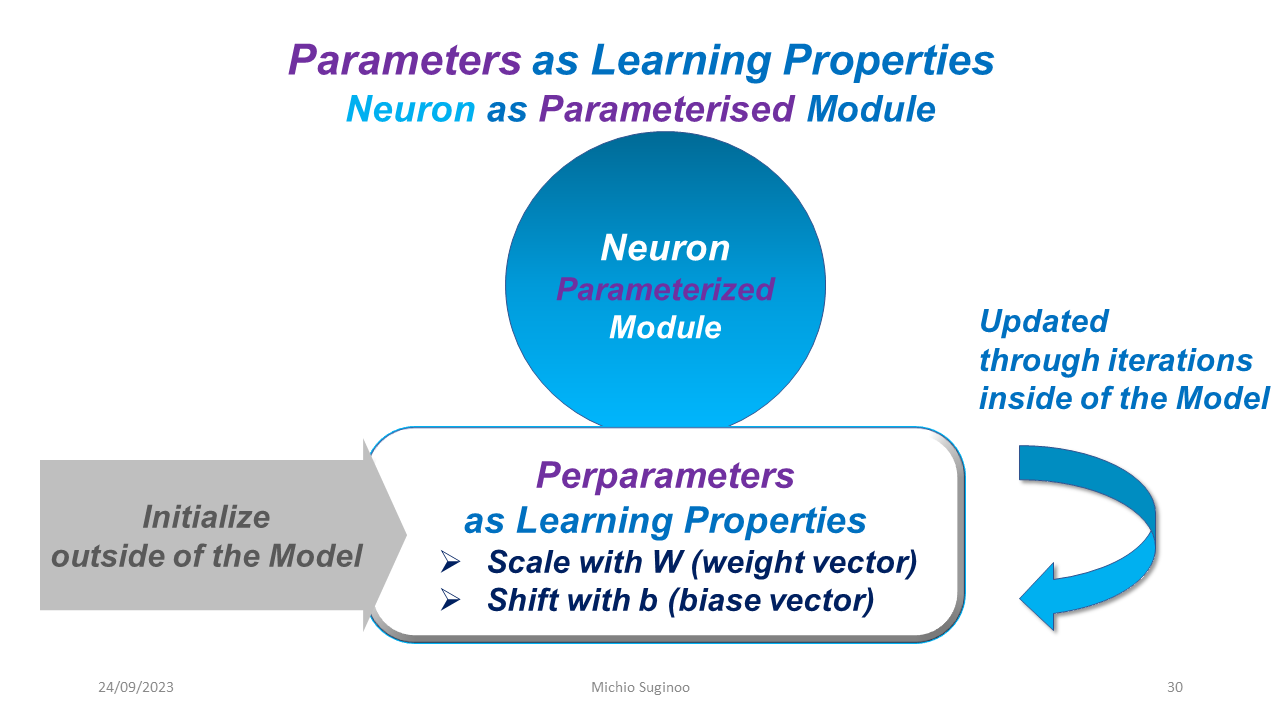
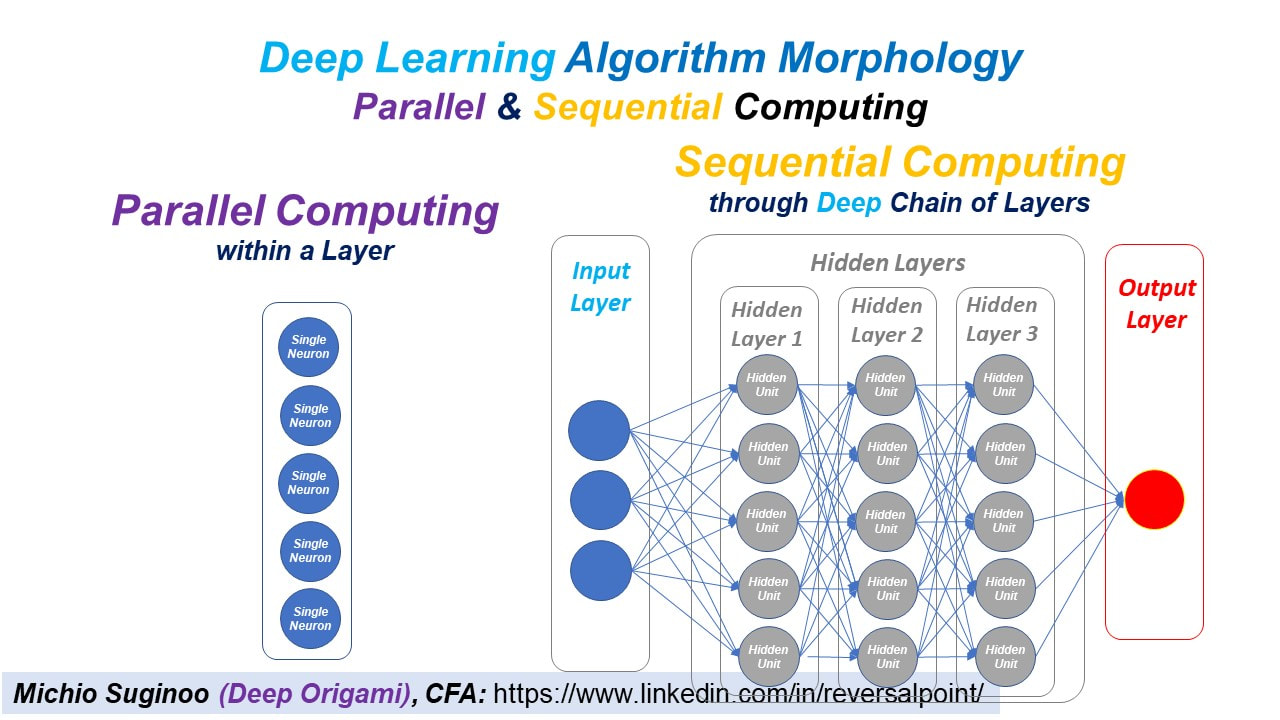
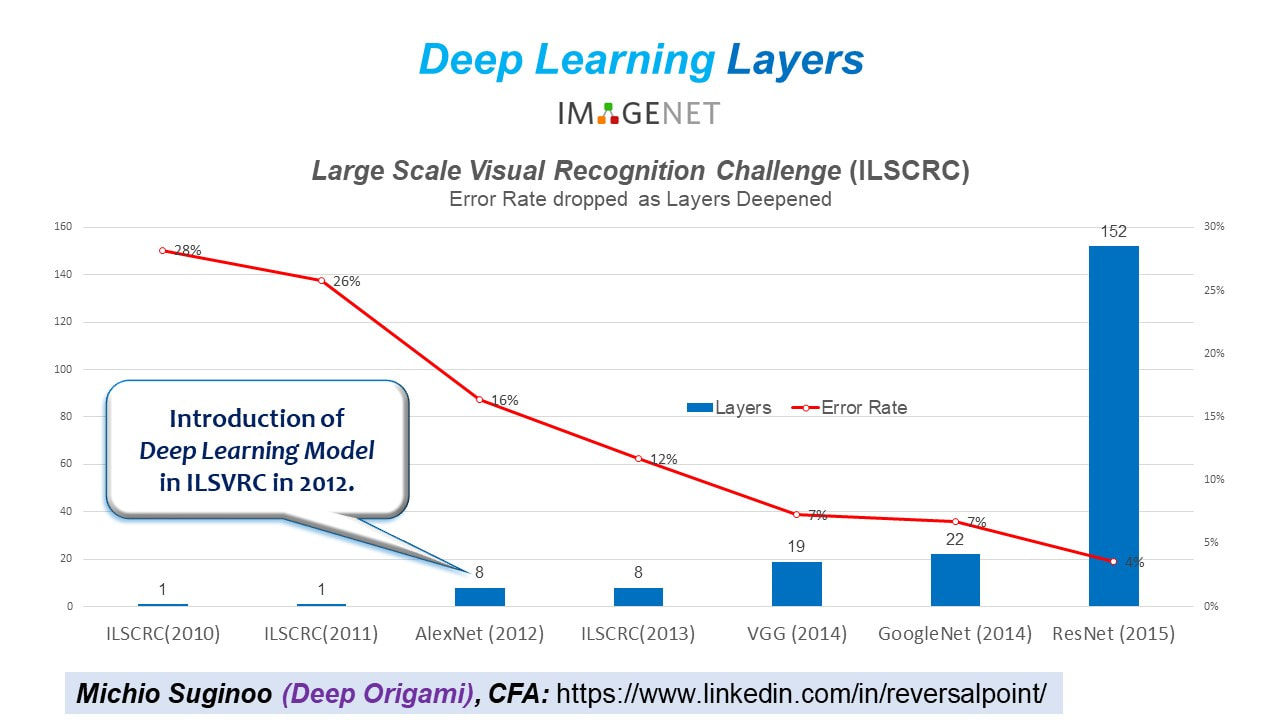
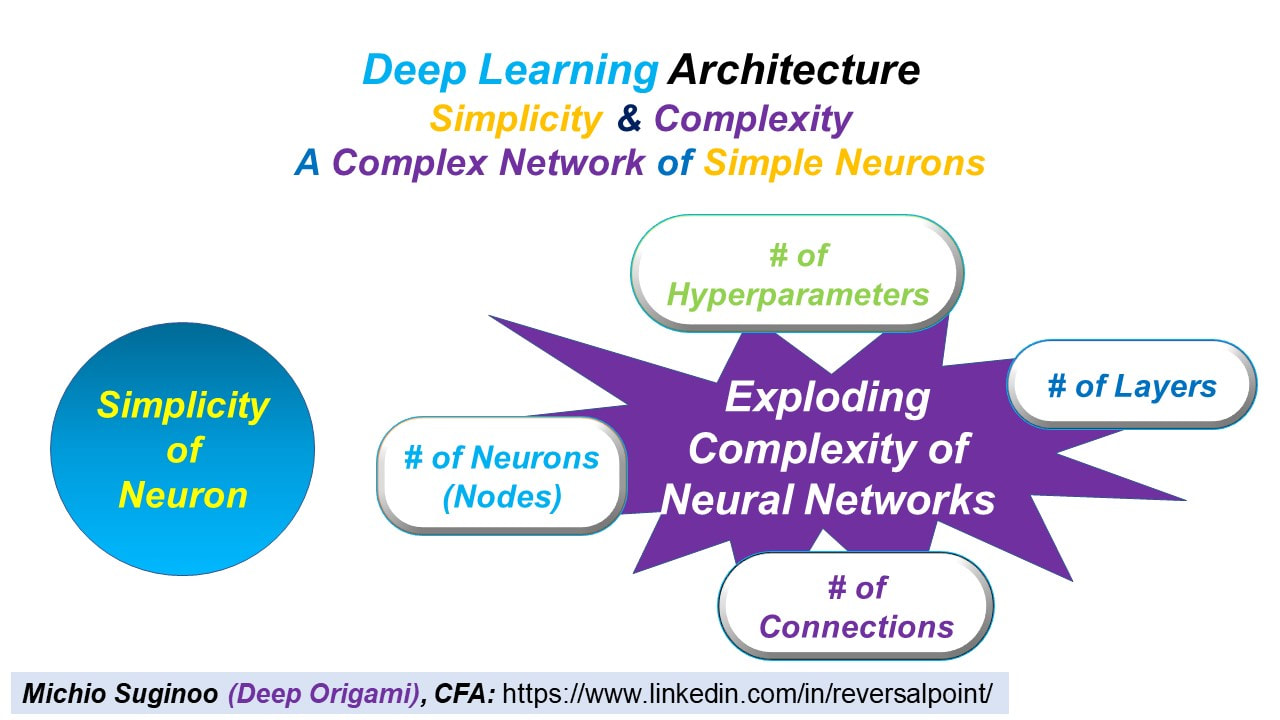
Series:
Basic Intuitions of Machine Learning & Deep Learning for beginners
Chapter 3: Deep Learning Connectionism Architecture
|
|
|
Chapter 3: Deep Learning Connectionism Architecture
|