Series: Basic Intuitions of Machine Learning & Deep Learning for beginners
Chapter 1: Machine Learning Algorithm Paradigm
Originally published: 16 February, 2021 Revised: 24 September, 2023 By Michio Suginoo
What is Machine Learning Algorithm Paradigm? How is it different from the Traditional Algorithm Paradigm? That is the theme of this chapter.
Footnote Remark: Basic Terminology
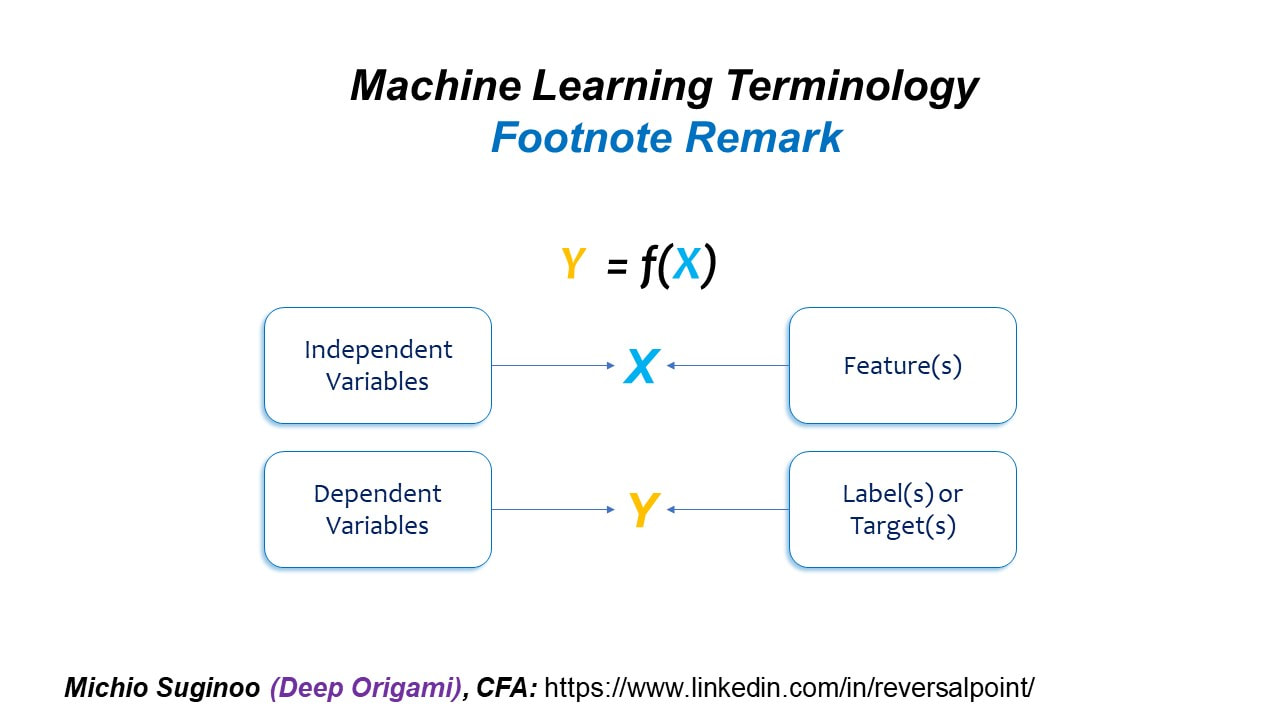
Before getting into Machine Learning topic, here is a footnote remark. Machine Learning has its own unique terminology.
As an example, here in the figure below, we have a simple equation: a dependent variable, Y, on the left is a function of an independent variable, X, on the right.
Following the convention of Machine Learning, I will call X Features, instead of Independent Variable; and Y Labels or Targets instead of Dependent Variable throughout this series.
The Limitation of Traditional Machine Learning Paradigm
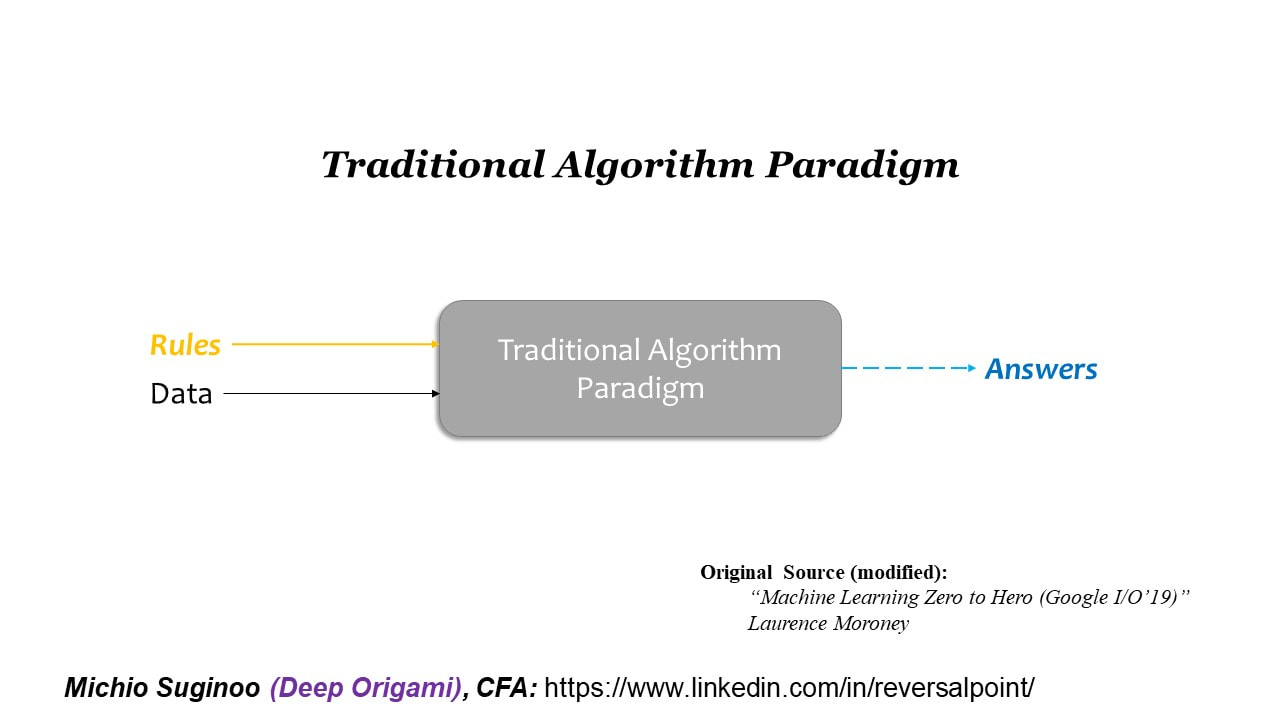
Now, in order to illustrate the mechanism of Machine Learning, let’s contrast it with the traditional algorithm paradigm. In the traditional algorithm paradigm, programmers explicitly pre-determine rules that map the input data into the answer. Naturally, in the workflow of the traditional algorithm paradigm, the rules come first. Overall, you have to have a good idea about the rules in advance. It is an intuitive approach.
The figure below illustrates this notion.
Now, here is a question. How can you set rules to detect the cat in the picture below?
In the traditional algorithm paradigm, you have to explicitly hand engineer appropriate rules in order to capture details such as eyes, ears, mouth, and so on. As the complexity of tasks increases, it would become progressively more difficult, or even impossible, to predetermine the rules.
Such a limitation of the traditional algorithm paradigm set the stage for the emergence of Machine Learning Paradigm.
Then, what is Machine Learning Paradigm? How does it address the limitation of the traditional algorithm paradigm? Machine Learning Paradigm
Here, for the sake of simplicity, we focus only on Supervised Machine Learning, where we have actual labels in the dataset.
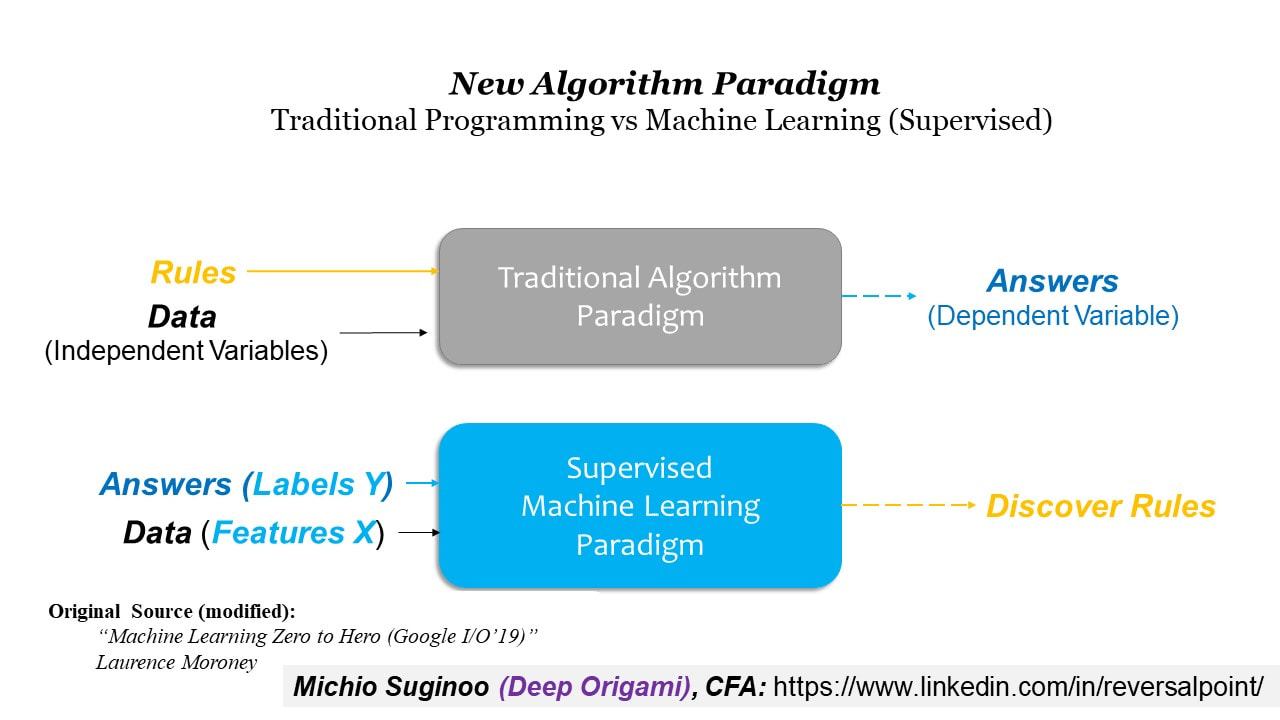
The next figure contrasts the fundamental difference between the traditional algorithm paradigm and Supervised Machine Learning Paradigm.
As you see at the bottom: in contrast to the traditional paradigm, Supervised Machine Learning has rules at the end; and the answers at the beginning. Its logic is totally opposite to the traditional logic.
The underlying idea here is that: “the sample dataset” supervises the machine to discover “the rules that map the Features into the given Labels.”
Thus, the name ‘Supervised’ comes from this notion that “a labelled dataset” supervises the machine.
Now, suppose that we do not have actual sample labels in the dataset, there is nothing to supervise the machine.
What shall we do?
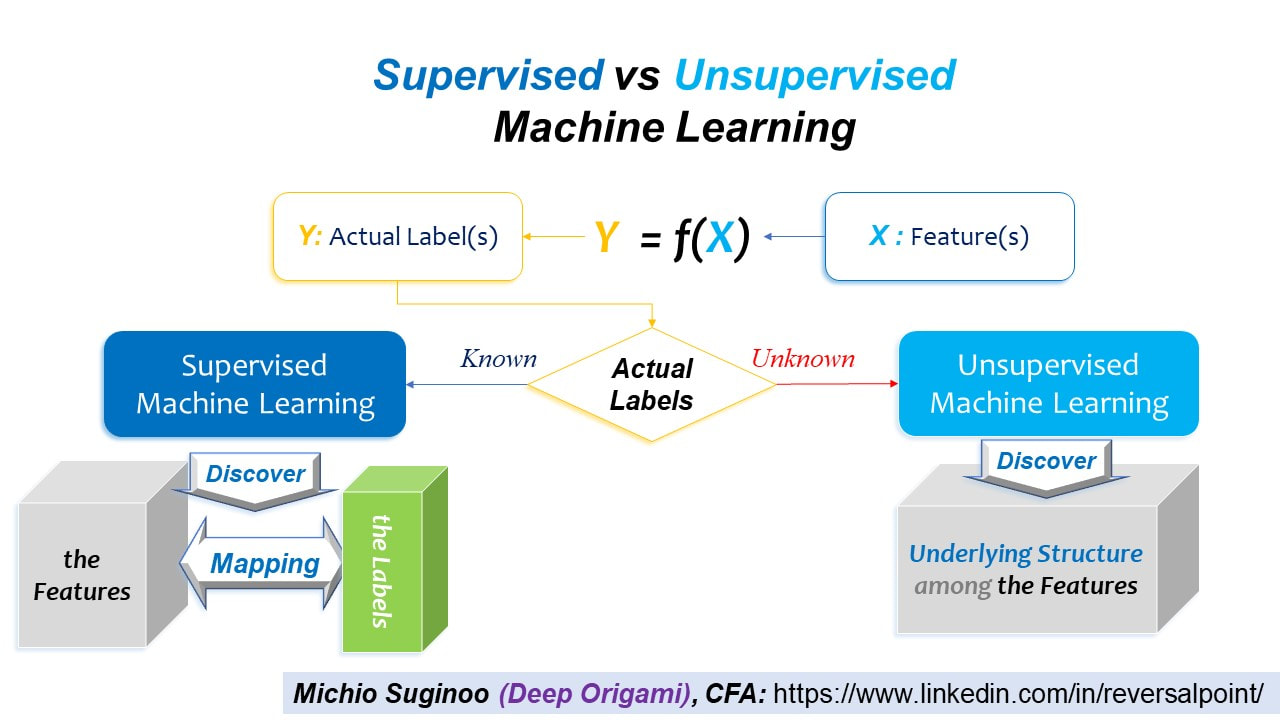
In such a case, we have to rely on ‘Unsupervised architecture’. The next figure contrasts between Supervised and Unsupervised architectures of Machine Learning.
Repeatedly, Supervised architectures discover the rules that map the Feature datasets to the Labels. In contrast, Unsupervised architectures, in the absence of the Labels, can only discover the underlying structure among the Feature dataset. Now, let’s take an overview of Machine Learning Family.
Overview of Machine Learning Family Tree
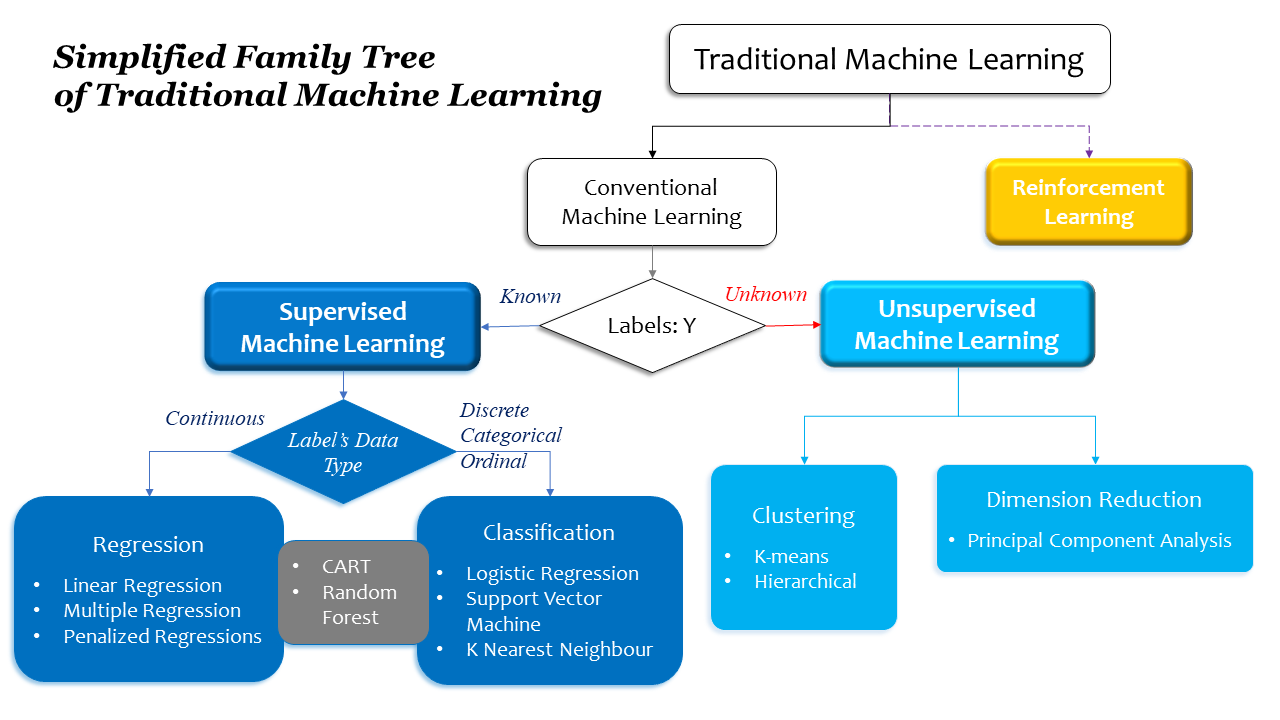
This family tree below organizes a variety of Machine Learning models in a structured way.
Here is a family tree of traditional machine learning algorithm.
The first division comes between Conventional Machine Learning or Reinforcement Learning. Conventional Machine Learning algorithms require IID, independently and identically distributed, as a necessary condition. It means that the dataset is collected using independent sampling methods from the same (identical) distribution. On the contrary, Reinforcement Learning algorithms have to learn from an ever changing environment; thus its architecture could not contemplate the IID property of the dataset. Reinforcement Learning applies Markov Process in its learning process.
Conventional Machine Learning are further divided into Supervised and Unsupervised, depending whether the dataset has labels or not.
In the Supervised space, the third division separates Regression and Classification based on the datatype of the output: whether continuous or discrete. Both cases have to have labels. In Classification, all the datapoints need to be classified into a set of given categorical labels.
In the Unsupervised space, I just put two popular types: clustering and dimension reduction. Clustering focuses on sorting observations into groups (clusters) based on the similarities and differences among datapoints.
Dimension Reduction focuses on compressing the dimensions of the dataset by discovering orthogonal natures of dataset. It reduces complexity of the model and improves computational efficiency of the model.
Those algorithm in the gray box inbetween Supervised and Unsupervised ML can be applied to both Supervised ML and Unsupervised ML.
When we look at the history of Machine Learning—especially Deep Learning—most successful applications evolved from Supervised architectures rather than Unsupervised ones. Nevertheless, in order to run Supervised models, programmers needed to manually label dataset in the past.
Nowadays, in order to alleviate “tedious manual labelling works”, there are some “data augmentation techniques” that generate fake but “realistic fake labelled dataset” out of a limited volume of actual samples. I personally call it ‘Good Fake’, in contrast to ‘Deep Fake’ which can be harmful to the society.
The reality of Unsupervised architecture today
All that said, there are some successful examples from Unsupervised Deep Learning space in the past. As an example, in the context of Deep Learning, Reinforcement Learning architecture played significant roles in some seminal breakthrough applications: especially in the world of Game.
Nevertheless, there is a critical limitation in Reinforcement Learning architecture. By design, it has to learn from its acts (trials). In order to learn what constitutes mistakes, a Reinforcement Learning model has to repeat thousands of mistakes. In this context, it demands enormous amount of training.
The big limitation to Reinforcement Learning is that it requires many trials for it to learn anything. If you want to use a kind of standard form of Reinforcement Learning to train a car to drive itself, it will have to drive millions of hours and cause thousands of accidents, if not tens of thousands, and kills many pedestrians before it learns how to drive. How is it for humans to drive a car only with a 20 hours of training? It is a big mystery.”
First, it would be risky to deploy crude Reinforcement Learning applications in Self-driving Car on the street.
Second, it would be computationally very inefficient.
Reinforcement Learning is not a promising model for the long term future, despite of the presence of its successful applications in games.
Given the reality of Unsupervised architecture today, LeCun stresses the need for a new form of Unsupervised architecture and articulates the potentiality of Self-Supervised model.
Reinforcement Learning: Framework Overview
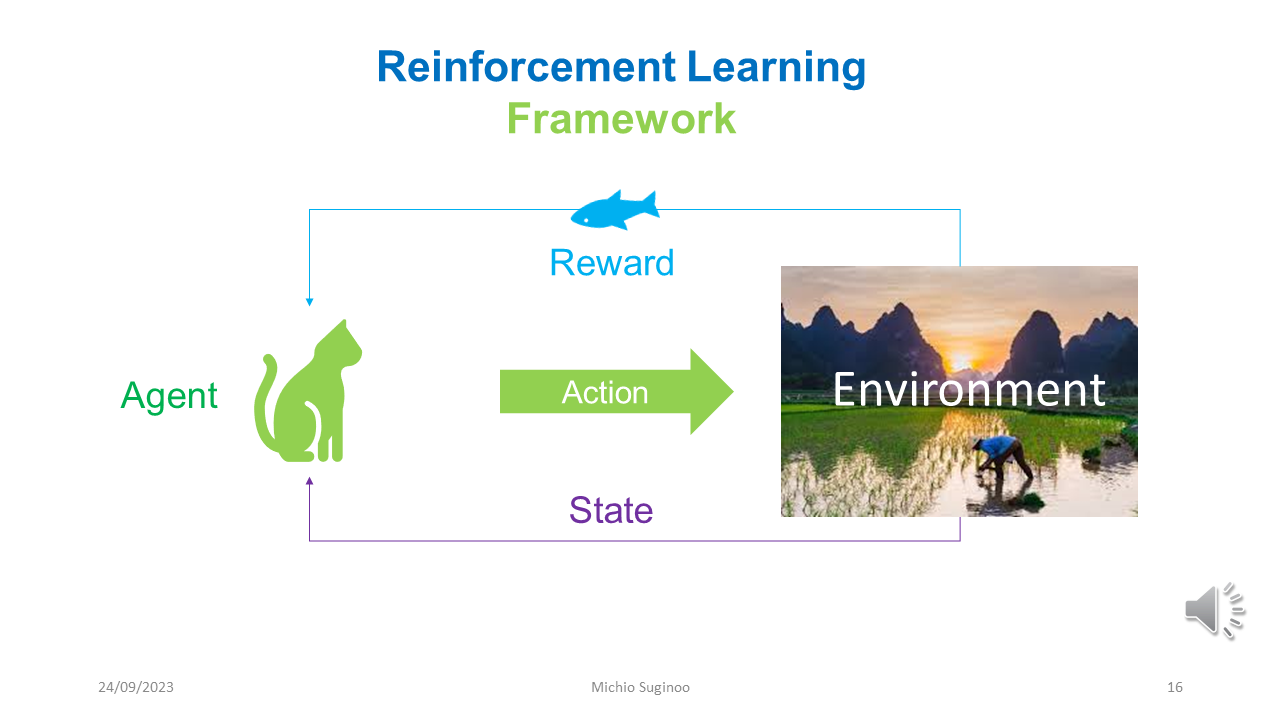
Now, here is a quick note about Reinforcement Learning. The image below outlines the framework of Reinforcement Learning.
In its framework, Reinforcement Learning has two essential components: an environment and an agent. The environment keep changing its state and it gives two things to the agent, the information about its state and rewards according to the agent's actions. And the agent acts according to the state of environment in an attempt to maximize its rewards.