Series: Basic Intuitions of Machine Learning & Deep Learning for beginners
Chapter 2: Generalization: Ultimate Goal of Machine Learning Project
Originally published 16 February, 2021 By Michio Suginoo
Revised: 29 Sptember, 2023
So, in Chapter 1, we got an intuition about Machine Learning Algorithm Paradigm. It is about training Machine on the given dataset: in the presence of actual labels, Supervised architecture can discover the hidden rules that map the Feature dataset to the Labels; in the absence of actual labels, Unsupervised architecture could discover the underlying structure within the Feature dataset.
All that said, an important thing is: training the machine is not good enough in the lab.
Ultimate Objective of Machine Learning: Generalization
The ultimate objective of Machine Learning is a generalization.
Imagine, if the trained dataset contained some anomalies or biases, the trained model might fail to perform well with other dataset drawn from the same distribution. This sort of risk is called Overfitting Risk.
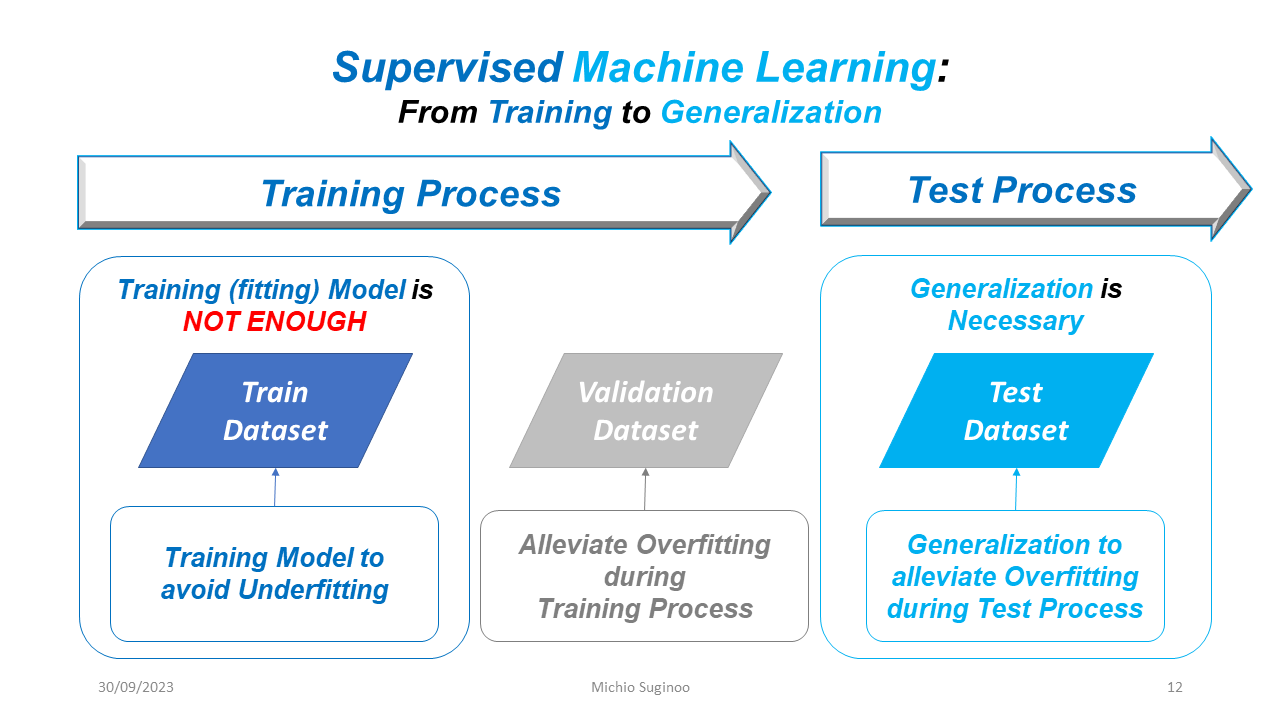
In order to address overfitting risk, we need to incorporate two steps into the model development workflow: validation during the training process and generalization during the testing process. In this spirit, in the lab, we divide the dataset into three subsets at least.
The figure below illustrate an example of three division.
Use “Train Dataset” and “Validation Dataset” during the training process.
Use "Train Dataset” to avoid underfitting
Use “Validation Dataset” to alleviate overfitting during the training process
Use “Test Dataset” for generalization to further alleviate overfitting risk during the test process
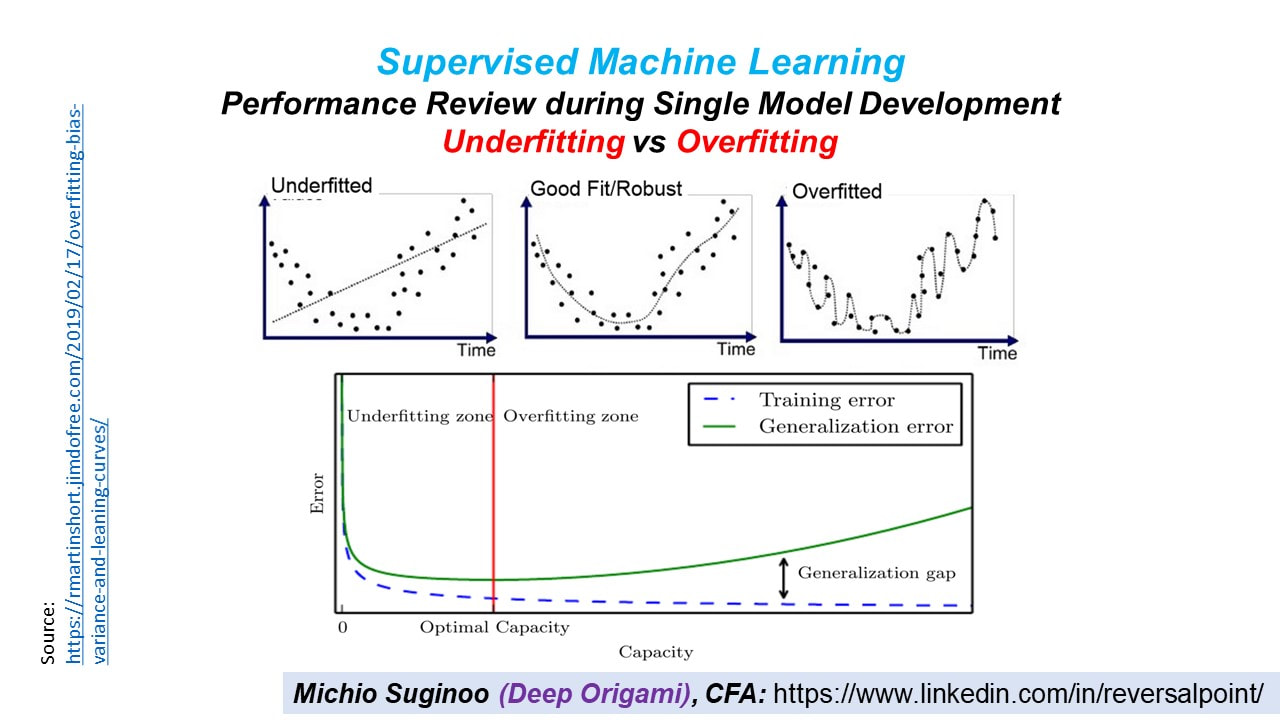
Now, let’s take a look at the next figure.
Here, we have 3 charts on the top to capture the 3 scenarios:
First, underfitting on the left; the straight line fails to represent the distribution of the given datapoints.
Then, overfitting on the right; the line connecting all the datapoints is a symptom of overfitting and would likely fail to represent the general distribution of the entire population.
and Robust Fit in the middle: this Middle Way gives up an optimal fitting.
The chart at the bottom shows two error curves:
Training Error and
Generalization Error (Test Error).
As we fit the model on the dataset, training error declines. On the other hand, after a certain level of fitting, the generalization error starts rising.
While we want to fit the model well on the training dataset, we do not want to end up failing the generalization of the model. So, in the lab we want to have a middle way at an optimal capacity, Robust Fit, to avoid both underfitting and overfitting risks.
Capacity
In the chart, the description of the X axis reads ‘Capacity’. Here is an excerpt from the famous deep learning text book. (Goodfellow, Bengio, & Courvil, 2016) “Informally, a model’s capacity is its ability to fit a wide variety of functions.
Models with low capacity may struggle to fit the training set.
Models with high capacity can overfit by memorizing properties of the training set that do not serve them well on the test set.
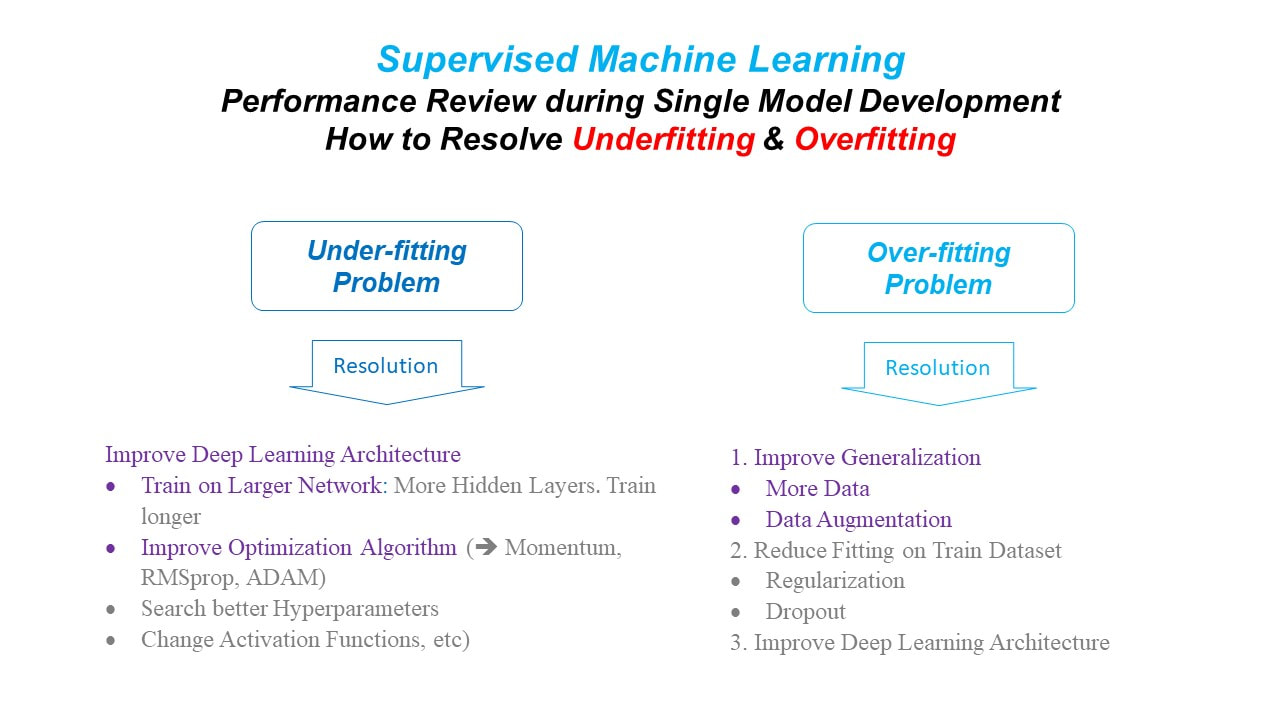
Addressing Overfitting & Underfitting
Now, how can we address the issues of underfitting and/or overfitting?
When your model is suffering from ‘underfitting’, the model has not been fitted enough on the given dataset. In such a case, we need to improve the architecture of the learning algorithm; rather than feeding more data. And there are the following options at least:
to train longer by extending the 3-step iteration cycle for a longer repetition (epochs)
to adjust the operating components of the learning algorithm: neurons, layers, activation functions, and other hyperparameters
to improve optimization techniques, which are beyond the scope of this series.
When your model is suffering from ‘overfitting’, the model was fitted too well to only the Train dataset. So, you want to explore the next options:
to feed in more data to improve the generalization of the model
to penalize fitting on Train Dataset: this is beyond the scope of this series.
to adjust Deep Learning architecture
For now, this is a preview to cultivate your high level understanding: you do not need to understand the details of these techniques at this stage. You will have a better understanding over these techniques in later stages of your Machine Learning journey.
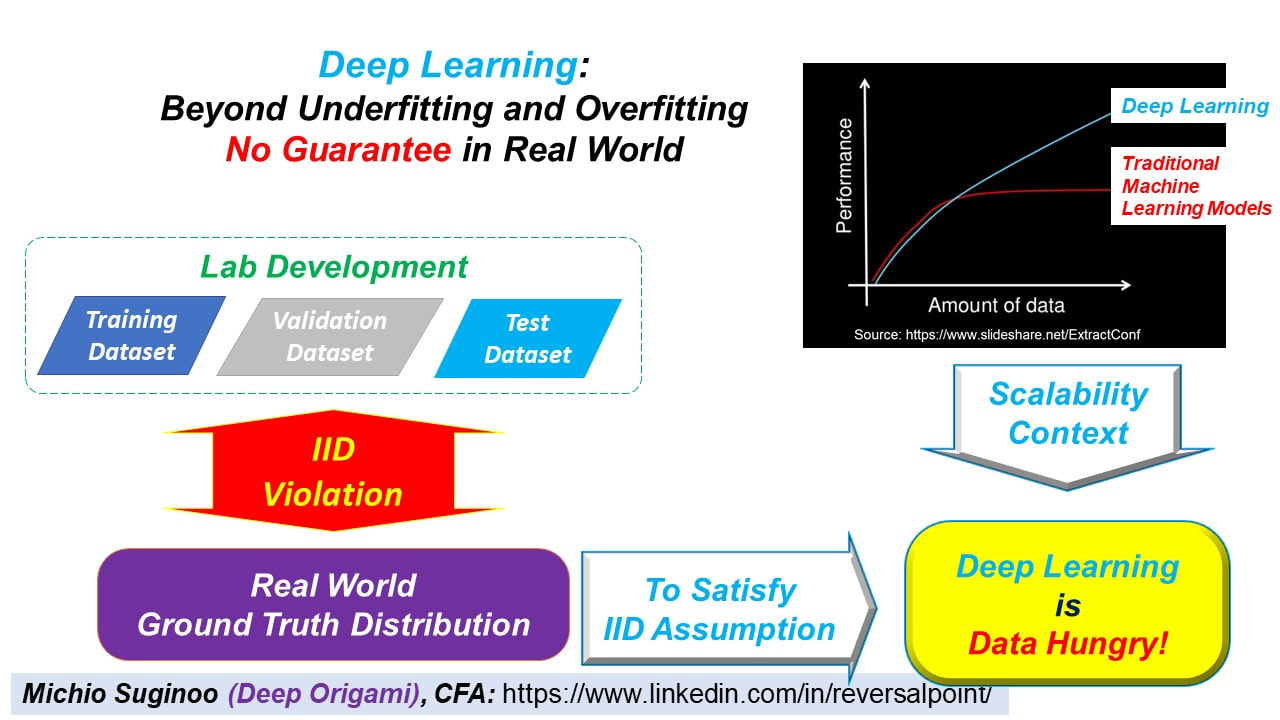
IID Violation Issue
Next, suppose that we fully addressed both underfitting and overfitting risks in the lab. Now, the model is validated in the lab. Is that “a happy ending”?
As a matter of fact, there is no guarantee, especially if there is a violation of the fundamental principle of IID Assumption; or “Independent and Identical Distribution Assumption”.
In an extreme situation, if those 3 datasets altogether failed to represent the real world ground truth distribution of the subject, “the validated model in the lab” could miserably fail in real world settings.
So, “the validated model in the lab” is only as good as the quality of the given dataset.
In order to meet IID Assumption, we need a massive amount of dataset. In addition, remember, Deep Learning is more scalable than “Traditional Machine Learning Models”
IID Assumption, together with Scalability Context, reinforces data hungry nature of Deep Learning more than Traditional Machine Learning Models.